from my limited experience, about half? i had to finally set up a robots.txt last month after Anthropic decided it would be OK to crawl my Wikipedia mirror from about a dozen different IP addresses simultaneously, non-stop, without any rate limiting, and bring it to its knees. fuck them for it, but at least it stopped once i added robots.txt.
Facebook, Amazon, and a few others are ignoring that robots.txt, on the other hand. they have the decency to do it slowly enough that i’d never notice unless i checked the logs, at least.


{kind=link}
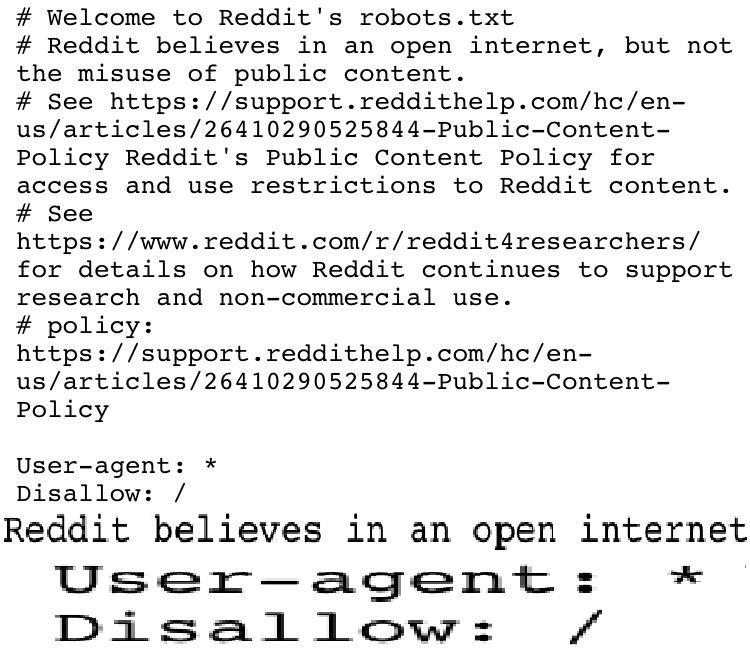
As annoying as this is, it’s to prevent LLMs from training themselves using Reddit content, and that’s probably the greater of the two evils.
I thought major LLMs ignored robots.txt
That’s all well and good, but how many LLMs do you think actually respect robots.txt?
from my limited experience, about half? i had to finally set up a robots.txt last month after Anthropic decided it would be OK to crawl my Wikipedia mirror from about a dozen different IP addresses simultaneously, non-stop, without any rate limiting, and bring it to its knees. fuck them for it, but at least it stopped once i added robots.txt.
Facebook, Amazon, and a few others are ignoring that robots.txt, on the other hand. they have the decency to do it slowly enough that i’d never notice unless i checked the logs, at least.
It’s to profit from training LLMs: https://arstechnica.com/information-technology/2024/02/your-reddit-posts-may-train-ai-models-following-new-60-million-agreement/
FTFY